
Welcome to the continuation of my series Getting Started with Python Integration to SAS Viya. Given the exciting developments around SAS & Snowflake, I’m eager to demonstrate how to effortlessly connect Snowflake to the massively parallel processing CAS server in SAS Viya with the Python SWAT package.
If you’re interested in learning more about SAS and Snowflake, feel free to check out this informative communities article, SAS partner page, or watch the SAS Viya release highlights.
Make a CAS connection
Starting off, I’ve taken the first steps of importing the required packages and establishing a connection between my Python client and the distributed CAS server in SAS Viya, which I’ve named conn. Now, I’ll proceed by executing the about CAS action to validate my connection to CAS and to retrieve information about the version of SAS Viya that I’m working with.
If you’re curious about setting up a CAS connection, you can find detailed instructions in one of my earlier blog posts.
import swat import pandas as pd ## Connect to CAS conn = swat.CAS(Enter your CAS connection information) ## View the version of SAS Viya conn.about()['About']['Viya Version'] ## and the results 'Stable 2024.01' |
The results show the connection was successful and the version of Viya is Stable 2024.01.
Connect the massively parallel processing CAS server to Snowflake
After establishing your connection to CAS, you will require a Snowflake account to make a connection. I have stored my Snowflake account information in a JSON file named snowflake_creds.json, structured as follows:
{ "account_url": "account.snowflakecomputing.com", "userName": "user-name", "password": "my-password" } |
Please follow any company policy regarding authentication. I’m using a demonstration Snowflake account.
To create a new connection to Snowflake, called a caslib, we’ll utilize the Snowflake SAS Viya Data Connector. This will connect the distributed CAS server to the Snowflake data warehouse. To create the caslib connection, you’ll require additional information from Snowflake. Details include:
- Snowflake connection information, such as your username, password, and the account URL, which I’ve stored in my JSON file. Again, follow all company policy regarding authentication.
- Database name: For demonstration purposes, I’ll utilize the sample database SNOWFLAKE_SAMPLE_DATA.
- Schema name: I’ll use the TPCH_SF10 schema.
After gathering these details, you can use the table.addCaslib action on your conn connection object to connect to Snowflake. I’ll name my caslib my_snow_db.
## Connect to CAS ## Get my Snowflake connection information from my JSON file my_json_file = open(os.getenv('CAS_CREDENTIALS') + '\snowflake_creds.json') snow_creds = json.load(my_json_file) ## Create a caslib to Snowflake using my specified connection information cr = conn.addcaslib(name = 'my_snow_db', datasource = dict( srctype = 'snowflake', server = snow_creds['account_url'], userName = snow_creds['userName'], password = snow_creds['password'], database = "SNOWFLAKE_SAMPLE_DATA", schema = "TPCH_SF10" ) ) ## and the results NOTE: 'my_snow_db' is now the active caslib. NOTE: Cloud Analytic Services added the caslib 'my_snow_db'. |
The results show that the Snowflake connection was added to the CAS server and named my_snow_db.
Explore the my_snow_db Caslib
I’ll use the fileInfo action to explore the available database tables in the my_snow_db caslib.
conn.fileInfo(caslib = 'my_snow_db') |
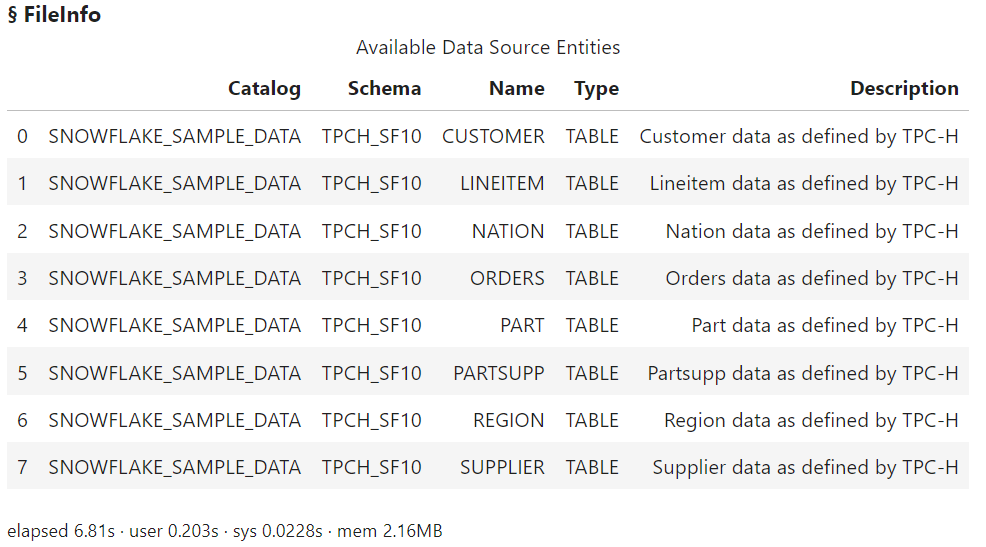
The results show we have a variety of database tables available in the SNOWFLAKE_SAMPLE_DATA.TPCH_SF10 schema.
Next, I’ll check if any tables are loaded in memory on the my_snow_db caslib.
conn.tableInfo(caslib = 'my_snow_db') ## and the results NOTE: No tables are available in caslib my_snow_db of Cloud Analytic Services. |
The results show that there are currently no in-memory items in the caslib, which is expected since we haven’t loaded anything in memory yet.
Execute SQL queries
To execute queries using the SWAT package, you first have to load the FedSQL action set. I have more information about executing SQL with the SWAT package in a previous post.
conn.loadActionSet('fedSQL') ## and the results NOTE: Added action set 'fedSQL'. § actionset fedSQL |
Writing FedSQL queries to Snowflake
I’ll start by executing a simple query to count the number of rows in the PART table within Snowflake. I’ll create a variable named totalRows to hold my query, and then I’ll utilize the execDirect action to execute the query. The query parameter specifies the query as a string. The method parameter is optional, but when set to True, it prints a brief description of the FedSQL query plan.
totalRows = ''' SELECT count(*) FROM my_snow_db.part ''' conn.execDirect(query = totalRows, method = True) |
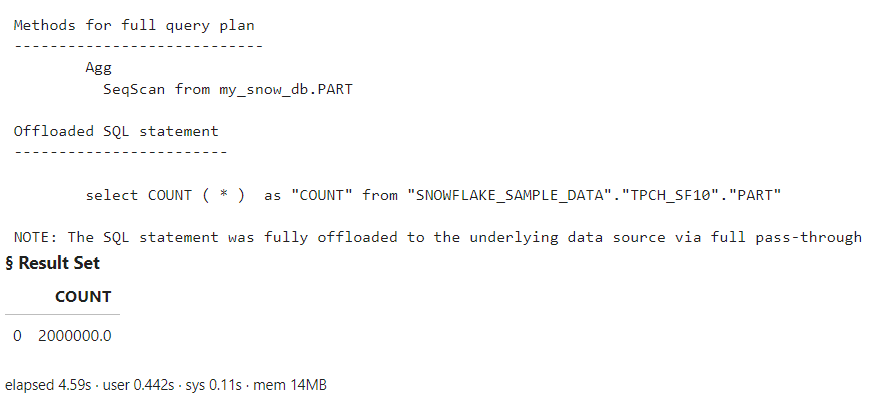
The results display the expected count from the PART table. However, the method parameter provides us with additional insights. It notes that our SQL statement was slightly modified and fully offloaded to the underlying data source via full pass-through. But what does that mean?
SAS Viya Data Connectors (along with SAS/ACCESS technology) strive to convert SAS SQL queries to run natively in the data source whenever possible. This is called implicit pass-through. In my experience, the more ANSI standard your queries are enhances the likelihood that SAS will push the processing directly in the database. This approach leverages the database computational power efficiently, retrieving only the necessary results.
I’ll run another query. This time I’ll count the number of rows within each P_MFGR group using the PART Snowflake table.
group_p_mfgr = ''' SELECT P_MFGR, count(*) FROM MY_SNOW_DB.PART GROUP BY P_MFGR ''' conn.execDirect(query = group_p_mfgr, method = True) |

The results confirm once more that the SAS FedSQL query was fully processed within Snowflake. You can see the entire SELECT statement that was run on Snowflake in the log.
Writing native Snowflake SQL through FedSQL (Explicit pass-through)
What if a coworker uses Snowflake SQL, while you work within SAS Viya and the Python SWAT package. Your coworker has written a Snowflake SQL query for you and sent it your way to summarize the data. You want to run it through the Python SWAT package to utilize the results for another process. What can you do? What if we just run the native Snowflake query? Let’s try it.
In the Snowflake documentation, there is an example query that addresses the business question: “The Pricing Summary Report Query provides a summary pricing report for all line items shipped as of a given date. The date is within 60-120 days of the greatest ship date contained in the database.” I’ll execute the Snowflake query through FedSQL as is.
snowflakeSQL = ''' select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1-l_discount)) as sum_disc_price, sum(l_extendedprice * (1-l_discount) * (1+l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.LINEITEM where l_shipdate <= dateadd(day, -90, to_date('1998-12-01')) group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus; ''' conn.execDirect(query = snowflakeSQL, method = True) ## and the results ERROR: Table "SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.LINEITEM" does not exist or cannot be accessed ERROR: The action stopped due to errors. |
The SQL we submitted contains Snowflake-specific syntax that other SQL processors like FedSQL don’t understand, generating an error.
Unlike most other SQL processors, FedSQL can send native SQL code directly to a database for execution, processing only the result set in FedSQL. We call this process “explicit pass-through”. A FedSQL explicit pass-through query is really made up of two separate queries: the inner query that executes in the database, and the outer query that processes the result set in FedSQL.
In the example below, the outer query merely selects all columns and rows from the result set returned from the database connected to the caslib specified by the CONNECTION TO keyword, in this case, my_snow_db. The pair of parenthesis encloses the inner query. Here, we’ve simply copied in the native Snowflake query code without any modifications.
snowflakeSQL = ''' SELECT * FROM CONNECTION TO MY_SNOW_DB (select l_returnflag, l_linestatus, sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price, sum(l_extendedprice * (1-l_discount)) as sum_disc_price, sum(l_extendedprice * (1-l_discount) * (1+l_tax)) as sum_charge, avg(l_quantity) as avg_qty, avg(l_extendedprice) as avg_price, avg(l_discount) as avg_disc, count(*) as count_order from SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.LINEITEM where l_shipdate <= dateadd(day, -90, to_date('1998-12-01')) group by l_returnflag, l_linestatus order by l_returnflag, l_linestatus); ''' conn.execDirect(query = snowflakeSQL, method = True) |
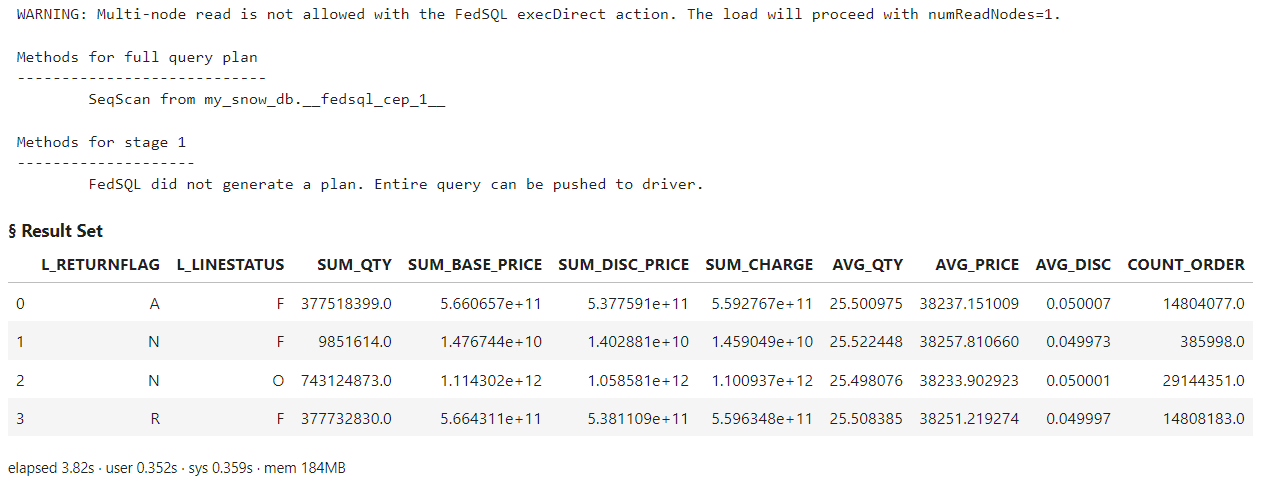
The log shows that FedSQL did not generate a plan because the entire query was explicitly sent to Snowflake as is and processed. Then, the results are displayed on the client. Instead of merely displaying the result set, I could have stored it in a DataFrame for further processing, or loaded it as a CAS table in the CAS server for additional advanced analytics or visualization using CAS actions, SAS Visual Analytics, or other Viya applications.
Forcing implicit pass-through
Lastly, what if you want to force the native FedSQL query to run in database to avoid transferring large data between CAS and Snowflake?
Let’s look at a simple example. I’ll view 10 rows from the PART Snowflake table using FedSQL.
myQuery = ''' SELECT * FROM MY_SNOW_DB.PART LIMIT 10 ''' conn.execDirect(query = myQuery, method = True) |
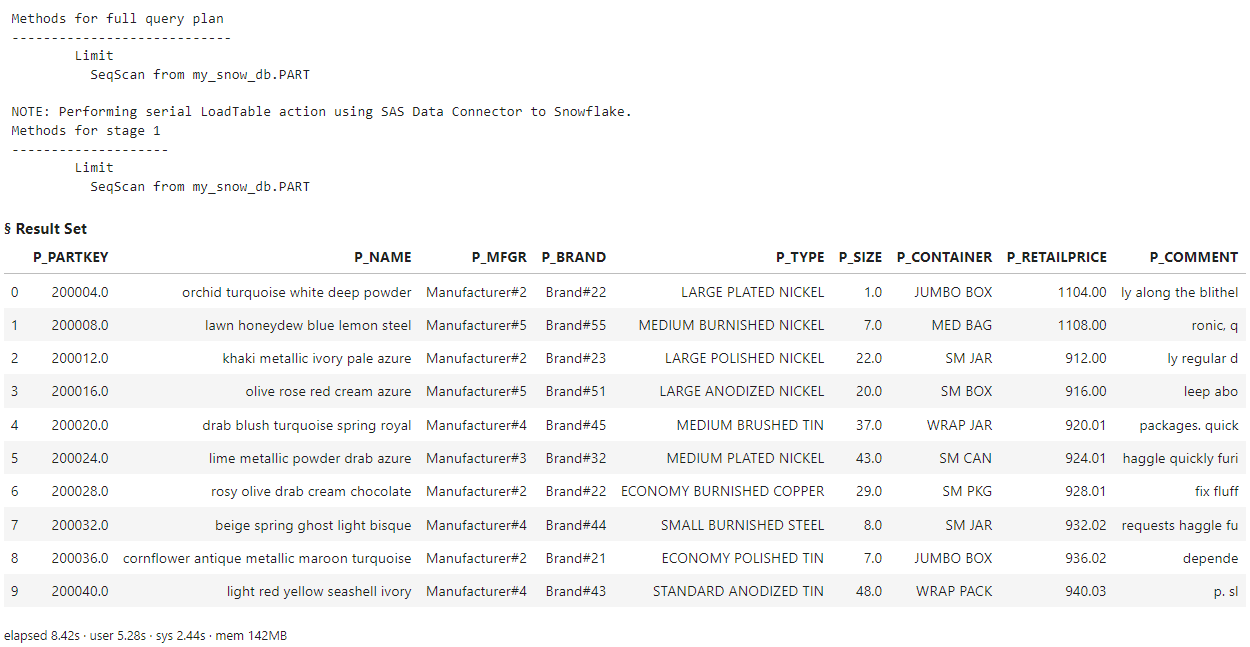
The log shows that the CAS server performed a serial load of the entire Snowflake table into CAS, then it limits the results to 10 rows. When executing a query that can’t be implicitly converted to run in database, all of the data is first automatically loaded into, and then processed by CAS. You get the desired results, but transferring large data from any data source to CAS can be inefficient and time consuming and should be avoided where possible.
One solution is to suppress the automatic action, ensuring the query either runs in the database (Snowflake) or returns an error. To do that, I like to use the CNTL parameter. It provides a wide variety of additional parameters to use when executing FedSQL. The parameter of interest here is requireFullPassThrough. Setting this parameter to True stops processing if FedSQL can’t implicitly pass-through the entire query to the database. In that case, no data is loaded into CAS, no output table or result set is produced, and a note is generated indicating what happened.
myQuery = ''' SELECT * FROM MY_SNOW_DB.PART LIMIT 10 ''' conn.execDirect(query = myQuery, method = True, cntl={'requireFullPassThrough':True}) |
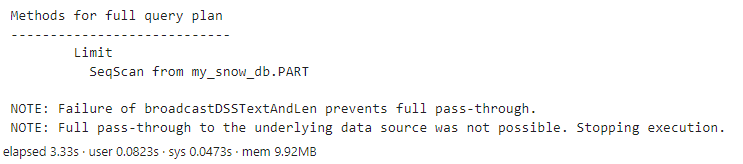
The log shows that since this FedSQL query could not be passed into Snowflake, the query stops prior to loading any of the Snowflake data into CAS.
If you encounter this and want to ensure your query runs in Snowflake to take advantage of it’s capabilities, simply modify the query or use explicit pass-through!
myQuery = ''' SELECT * FROM CONNECTION TO MY_SNOW_DB (SELECT * exclude(P_COMMENT, P_NAME) FROM SNOWFLAKE_SAMPLE_DATA.TPCH_SF10.PART LIMIT 10) ''' conn.execDirect(query = myQuery, method = True) |
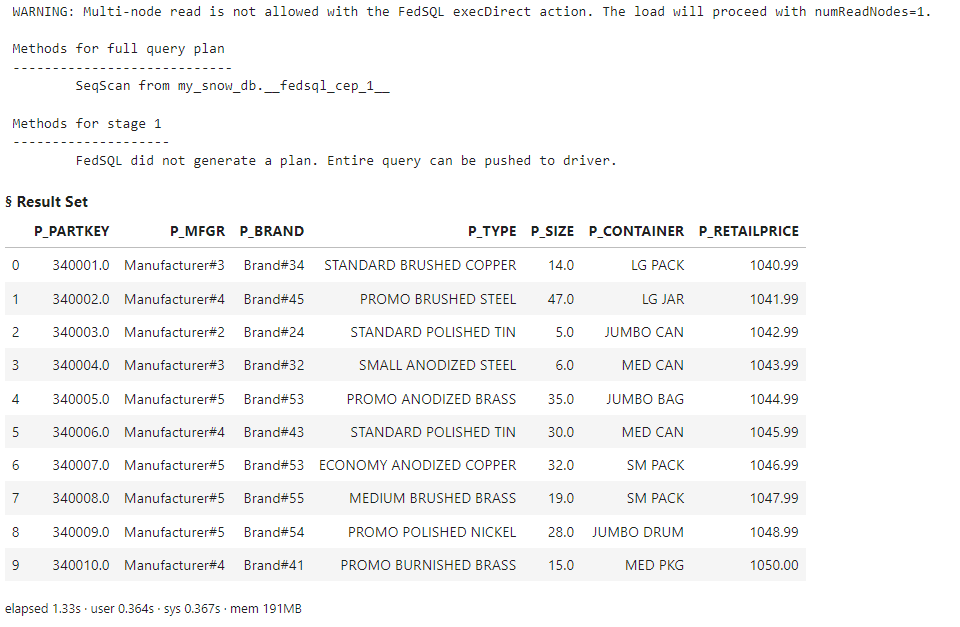
The log shows that the Snowflake SQL query was pushed directly to Snowflake for execution, and the results are returned to the client.
Summary
The SWAT package combines the power of the pandas API, SQL, and CAS actions to handle distributed data processing. In this example, I demonstrated executing implicit and explicit queries in Snowflake through the Snowflake Data Connector.
In the next blog post, I’ll illustrate how to load data from Snowflake into CAS to leverage specific Viya analytic actions and other SAS Viya applications.
For more efficiency tips and tricks when working with databases, check out the SAS course Efficiency Tips for Database Programming in SAS®.



