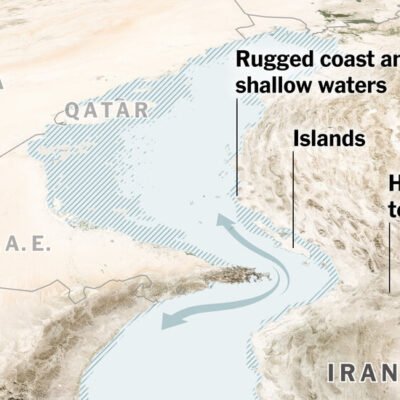
![]() Kevin Roose / New York Times:
Kevin Roose / New York Times:
A study of 14K web domains in the C4, RefinedWeb, and Dolma AI training datasets: 5% of all the data, and 25% of the highest-quality data, has been restricted — New research from the Data Provenance Initiative has found a dramatic drop in content made available to the collections used to build artificial intelligence.
Source link