Editor's note: This article follows Natural language processing techniques that improve data quality with LLMs.
Large language models (LLMs) have revolutionized the field of artificial intelligence by enabling machines to generate human-like responses based on extensive training on massive amounts of data. When using LLMs, managing toxicity, bias, and bad actors is critical for trustworthy outcomes. Let’s explore what organizations should be thinking about when addressing these important areas.
Understanding toxicity and bias in LLMs
The impressive capabilities of LLMs come with significant challenges, like the inadvertent learning and propagation of toxic and biased language. Toxicity refers to the generation of harmful, abusive, or inappropriate content, while bias involves the reinforcement of unfair prejudices or stereotypes. Both can lead to discriminatory outputs and negatively affecting individuals and communities.
Identifying and managing toxicity and bias
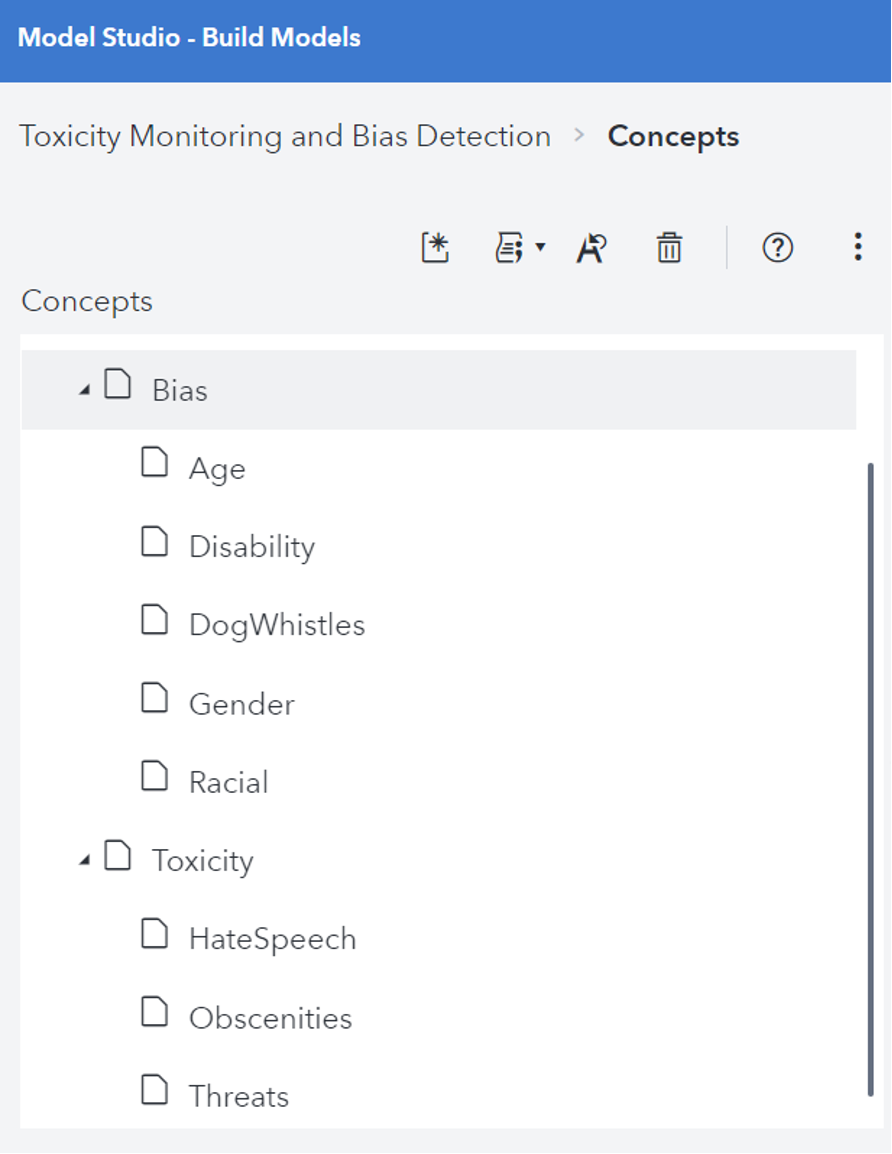
One obstacle in addressing toxicity and bias is the lack of transparency about the data used to pretrain many LLMs. Without visibility into the training data, it can be difficult to understand the extent of these issues in the models. Because it’s necessary to expose off-the-shelf models to domain-specific data to address business related use-cases, organizations have an opportunity to do due diligence and work to ensure that any data they introduce into the LLM doesn’t compound or exacerbate the problem.
While many LLM providers offer content moderation APIs and tools to mitigate the effects of toxicity and bias, they may not be sufficient. In my previous article, I introduced the SAS NLP powerhouse, LITI. Beyond addressing data quality issues, LITI can be instrumental in identifying and prefiltering content for toxicity and bias. By combining LITI with exploratory SAS NLP techniques such as topic analysis, organizations can gain a deeper understanding of potential problematic content in their text data. This proactive approach allows them to mitigate issues before integrating the data into LLMs through retrieval-augmented generation (RAG) or fine-tuning.
The models used for prefiltering content can also act as an intermediary between the LLM and the end user, detecting and preventing exposure to problematic content. This dual-layer protection not only enhances the quality of outputs but also safeguards users from potential harm. Having the ability to target specific types of language related to facets like hate speech, threats, or obscenities adds an additional layer of security and gives organizations the flexibility to address potential concerns that may be unique to their business. Because these models can address nuances in language, they could also be used to detect more subtle, targeted biases, like political dog whistles.
Bias and toxicity are important areas to continue to have humans in the loop to provide oversight. Automated tools can significantly reduce the incidence of toxicity and bias, but they are not infallible. Continuous monitoring and reviews are essential to catch instances that automated systems might miss. This is particularly critical in dynamic environments where new types of harmful content can emerge over time. As new trends develop, LITI models can be augmented to account for them.
Addressing manipulation by bad actors
Toxic or biased outputs from LLMs are not always due to inherent flaws in the training data. In some cases, models may exhibit unwanted behavior because they are being manipulated by bad actors. This can include deliberate attempts to exploit weaknesses in the models through malicious prompt injection or jailbreaking.
Malicious prompt injection is a type of security attack against LLMs. This involves concatenating malicious inputs with benign, expected inputs with the goal of altering the expected output. Malicious prompt injection is used to do things such as acquire sensitive data, execute malicious code, forcing a model to return or ignore its instructions.
A second type of attack is a jailbreak attack. It differs from malicious prompt injection in that in jailbreak attacks none of the prompts are benign. This research shows some examples of jailbreaking involving using prompt suffixes. One prompt asks the model for an outline to steal from a non-profit organization. Without a prompt suffix, the model responds that it can’t assist with that. Adding a prompt suffix results in the model bypassing its protections and generates a response. Jailbreaking and malicious prompt injection can involve exposing the model to nonsensical or repetitive patterns, hidden UTF-8 characters, and combinations of characters that would be unexpected in a typical user prompt. LITI is a great tool for identifying patterns, making it a powerful addition to a testing or content moderation toolbox.
Developing with responsible AI
Research into creating fair, unbiased, and non-toxic LLMs is ongoing, and requires a multifaceted approach that combines advanced technological tools with human oversight and a commitment to ethical AI practices. Powerful tools like LITI combined with robust monitoring strategies can help organizations significantly reduce the impact of toxicity and bias in their LLM outputs. This not only enhances user trust but also contributes to the broader goal of developing responsible AI systems that benefit society without causing harm.
Research extras
This is a serious topic, so I thought I’d leave you with something that made me laugh. As I was searching through articles looking for some examples to tie in with my section on bad actors, Bing tapped out. I did resist the urge to try a little prompt injection to see if I could get it to give me a better response.