
Zagadnienia związane z listami sankcyjnymi są obecne w życiu organizacji finansowych od wielu lat. Jednak to właśnie teraz nadszedł czas na przyjrzenie się, w jaki sposób temat ten jest zaadresowany zarówno pod kątem podejścia biznesowego, jak i zastosowanych algorytmów analitycznych.
Ostatnie kilka lat to zmiana regulacji w Unii Europejskiej, co bezpośrednio wpływa na zmiany prawne w każdym kraju członkowskim. Jako ukonstytuowanie tych zmian warto podać utworzenie osobnego organu w UE ds. AML (AMLA – Authority for Anti-Money Laundering and Countering the Financing of Terrorism). Dodatkowo z uwagi na sytuację geopolityczną w najbliższym otoczeniu Polski, ale też na świecie, liczba wpisów na listach sankcyjnych wzrosła diametralnie. Sam ten fakt powoduje powiększenie się wolumenu danych, które są porównywane z danymi klientów. Generuje to większe skomplikowanie tej samej operacji pod kątem skuteczności, czyli użytych metod analitycznych oraz AI, a także pod kątem niezbędnej infrastruktury technicznej dla systemu AML/CTF. W tym momencie często okazuje się, że istniejące systemy nie są wystarczające i pojawia się pytanie – czym je zastąpić.
Temat jest pozornie prosty. Osoba, czy też organizacja widniejąca na listach sankcyjnych, nie może współpracować z instytucją na terenie UE. Wydawać by się mogło, że to jedynie porównanie dwóch rekordów – danych prospekta z danymi na liście. Niestety często pomijanym aspektem są tutaj zagadnienia dotyczące tzw. Data Quality i samych zapisów informacji o kliencie. Przykładem mogą być różnice semantyczne w regionach pochodzenia klienta, nieznajomość specyfiki danego języka i różnic regionalnych przez pracowników instytucji finansowych, dopuszczalne różne zapisy adresu klienta itd. Rozwiązaniem dla tych wyzwań jest podejście holistyczne do zagadnienia dopasowywania (matchowania) danych klientów i prospektów z listami sankcyjnymi.
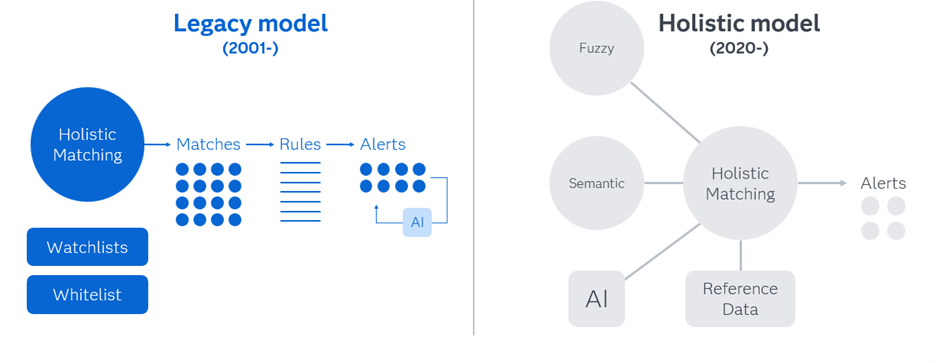
Jak takie dopasowanie działa w systemie SAS?
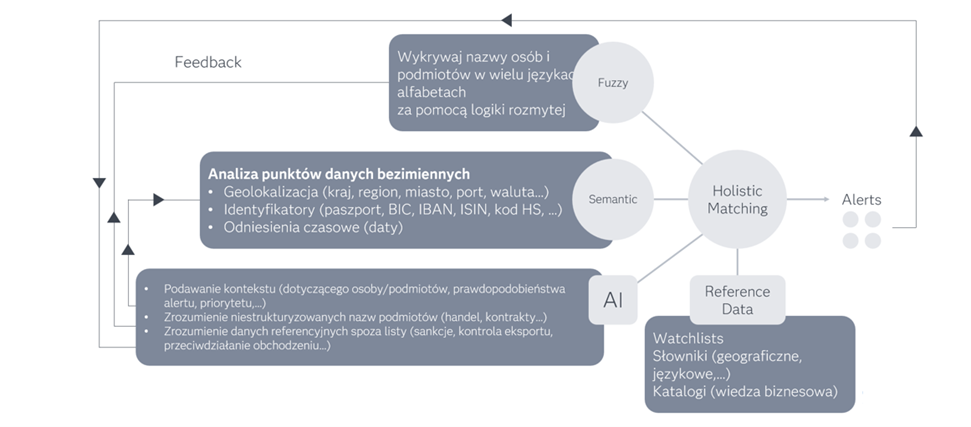
- W celu dopasowania różnych elementów danych, stosujemy podejście „dopasowania semantycznego”, w którym dla każdego typu punktu danych wywoływany jest określony algorytm dopasowywania. Na przykład „dopasowanie rozmyte” zostanie użyte do dopasowania nazw, podczas gdy (konfigurowalny) próg odległości zostanie użyty do „dopasowania” dwóch lokalizacji geograficznych na podstawie ich współrzędnych GPS. Podobnie, dopasowywanie dat (np. daty urodzenia) będzie przebiegać zgodnie z jeszcze innym określonym podejściem, umożliwiającym konfigurowalną tolerancję n
- Aby optymalnie dopasować nazwy, przed próbą „dopasowania rozmytego” stosujemy model AI/ML w celu wykonania prognozy pokrewieństwa kulturowego, aby wykryć pochodzenie nazwy. Jest to kluczowe, ponieważ struktury nazw różnią się w zależności od kultury, co wymaga dostosowanego podejścia do ważenia, w celu dopasowania różnych części nazwy.
- Wykorzystanie pokrewieństwa kulturowego do dynamicznego dostrajania silnika dla każdego pojedynczego żądania znacznie zwiększa wydajność, unikając przypadków fałszywych wyników pozytywnych. Obsługujemy wykrywanie pokrewieństwa kulturowego dla następujących języków: arabski, koreański, chiński, rosyjski, wietnamski, włoski, hiszpański i japoński. W przypadku niektórych z tych języków wdrażamy określoną strategię dopasowywania.
- Silnik oparty na logice rozmytej jest w stanie dopasować dwa nazwiska, które są pisane inaczej, na przykład z powodu odwróconych liter (John, vs Jhon), podwójnych liter lub brakujących podwójnych liter (Matter vs. Mater), brakujących liter lub nieoczekiwanych liter (entertainment vs entertainment), liter o podobnej wymowie (Selenskiy vs Zelenskiy), rozdzielonych/połączonych słów (Manpower Services vs Man Power Services).
Na koniec wszystkie pozytywne dopasowania wygenerowane przez silnik Neterium są przetwarzane przez reguły/modele RWS w celu ustalenia, które dopasowania skutkują alertami dostarczanymi do przeglądu przez analityków.
Zachęcam do obejrzenia webinaru, gdzie zaprezentowane zostało działanie systemu SAS do screeningu sankcji: Real-Time Watchlist Screening: Unlocking Efficiency and Compliance With SAS and Neterium



