
When people ask about the future of Generative AI in coding, what they
often want to know is: Will there be a point where Large Language Models can
autonomously generate and maintain a working software application? Will we
be able to just author a natural language specification, hit “generate” and
walk away, and AI will be able to do all the coding, testing and deployment
for us?
To learn more about where we are today, and what would have to be solved
on a path from today to a future like that, we ran some experiments to see
how far we could push the autonomy of Generative AI code generation with a
simple application, today. The standard and the quality lens applied to
the results is the use case of developing digital products, business
application software, the type of software that I’ve been building most in
my career. For example, I’ve worked a lot on large retail and listings
websites, systems that typically provide RESTful APIs, store data into
relational databases, send events to each other. Risk assessments and
definitions of what good code looks like will be different for other
situations.
The main goal was to learn about AI’s capabilities. A Spring Boot
application like the one in our setup can probably be written in 1-2 hours
by an experienced developer with a powerful IDE, and we don’t even bootstrap
things that much in real life. However, it was an interesting test case to
explore our main question: How might we push autonomy and repeatability of
AI code generation?
For the vast majority of our iterations, we used Claude-Sonnet models
(either 3.7 or 4). These in our experience consistently show the highest
coding capabilities of the available LLMs, so we found them the most
suitable for this experiment.
The strategies
We employed a set of “strategies” one by one to see if and how they can
improve the reliability of the generation and quality of the generated
code. All of the strategies were used to improve the probability that the
setup generates a working, tested and high quality codebase without human
intervention. They were all attempts to introduce more control into the
generation process.
Choice of the tech stack
We chose a simple “CRUD” API backend (Create, Read, Update, Delete)
implemented in Spring Boot as the goal of the generation.
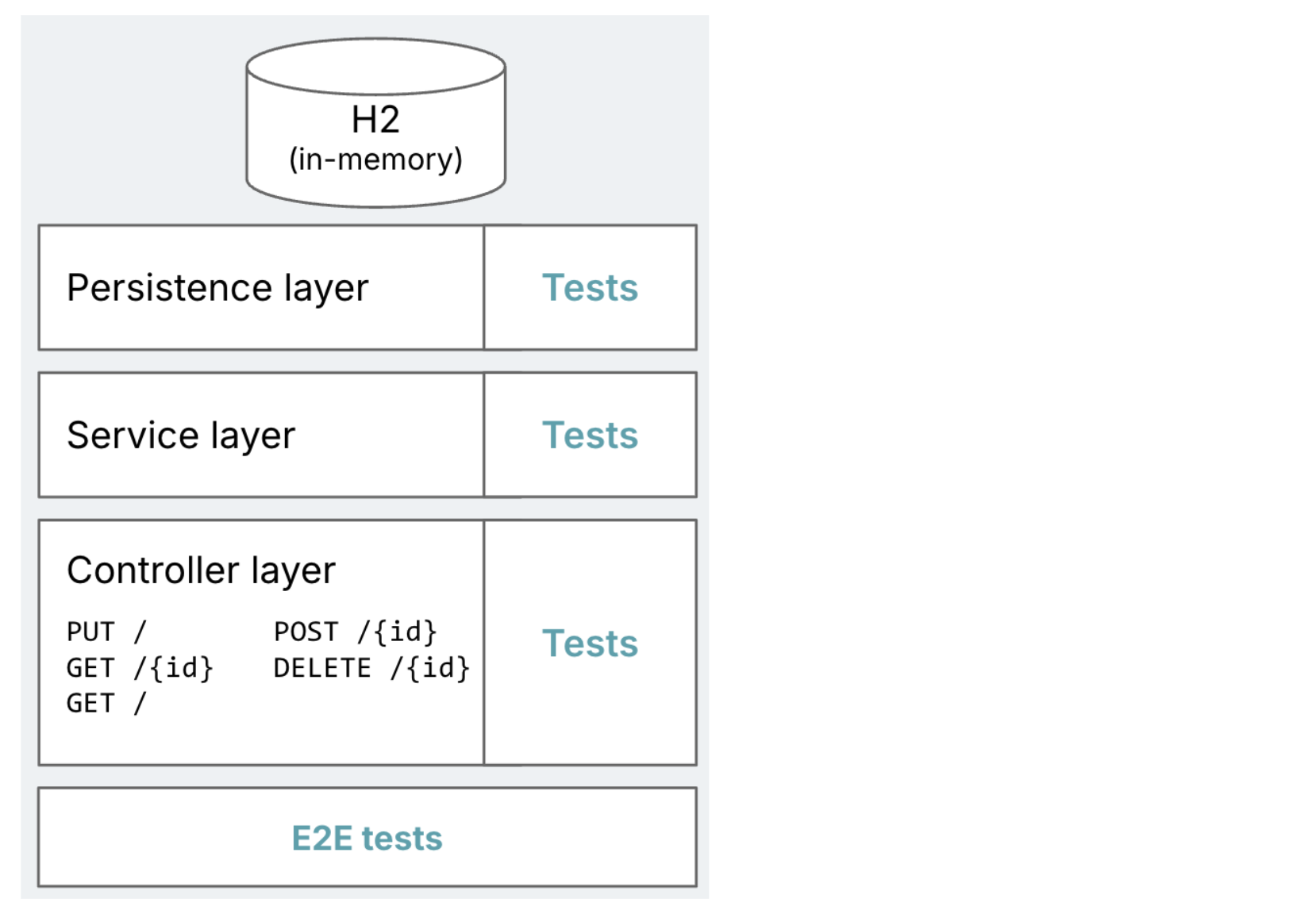
Figure 1: Diagram of the intended
target application, with typical Spring Boot layers of persistence,
services, and controllers. Highlights how each layer should have tests,
plus a set of E2E tests.
As mentioned before, building an application like this is a quite
simple use case. The idea was to start very simple, and then if that
works, crank up the complexity or variety of requirements.
How can this increase the success rate?
The choice of Spring Boot as the target stack was in itself our first
strategy of increasing the chances of success.
- A common tech stack that should be quite prevalent in the training
data - A runtime framework that can do a lot of the heavy lifting, which means
less code to generate for AI - An application topology that has very clearly established patterns:
Controller -> Service -> Repository -> Entity, which means that it is
relatively easy to give AI a set of patterns to follow
Multiple agents
We split the generation process into multiple agents. “Agent” here
means that each of these steps is handled by a separate LLM session, with
a specific role and instruction set. We did not make any other
configurations per step for now, e.g. we did not use different models for
different steps.
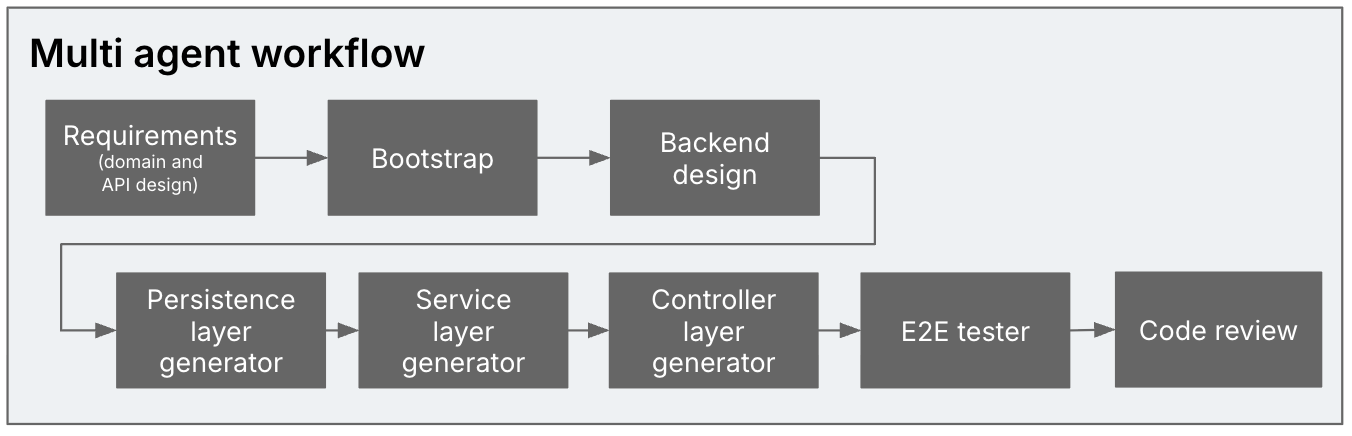
Figure 2: Multiple agents in the generation
process: Requirements analyst -> Bootstrapper -> Backend designer ->
Persistence layer generator -> Service layer generator -> Controller layer
generator -> E2E tester -> Code reviewer
To not taint the results with subpar coding abilities, we used a setup
on top of an existing coding assistant that has a bunch of coding-specific
abilities already: It can read and search a codebase, react to linting
errors, retry when it fails, and so on. We needed one that can orchestrate
subtasks with their own context window. The only one we were aware of at the time
that can do that is Roo Code, and
its fork Kilo Code. We used the latter. This gave
us a facsimile of a multi-agent coding setup without having to build
something from scratch.
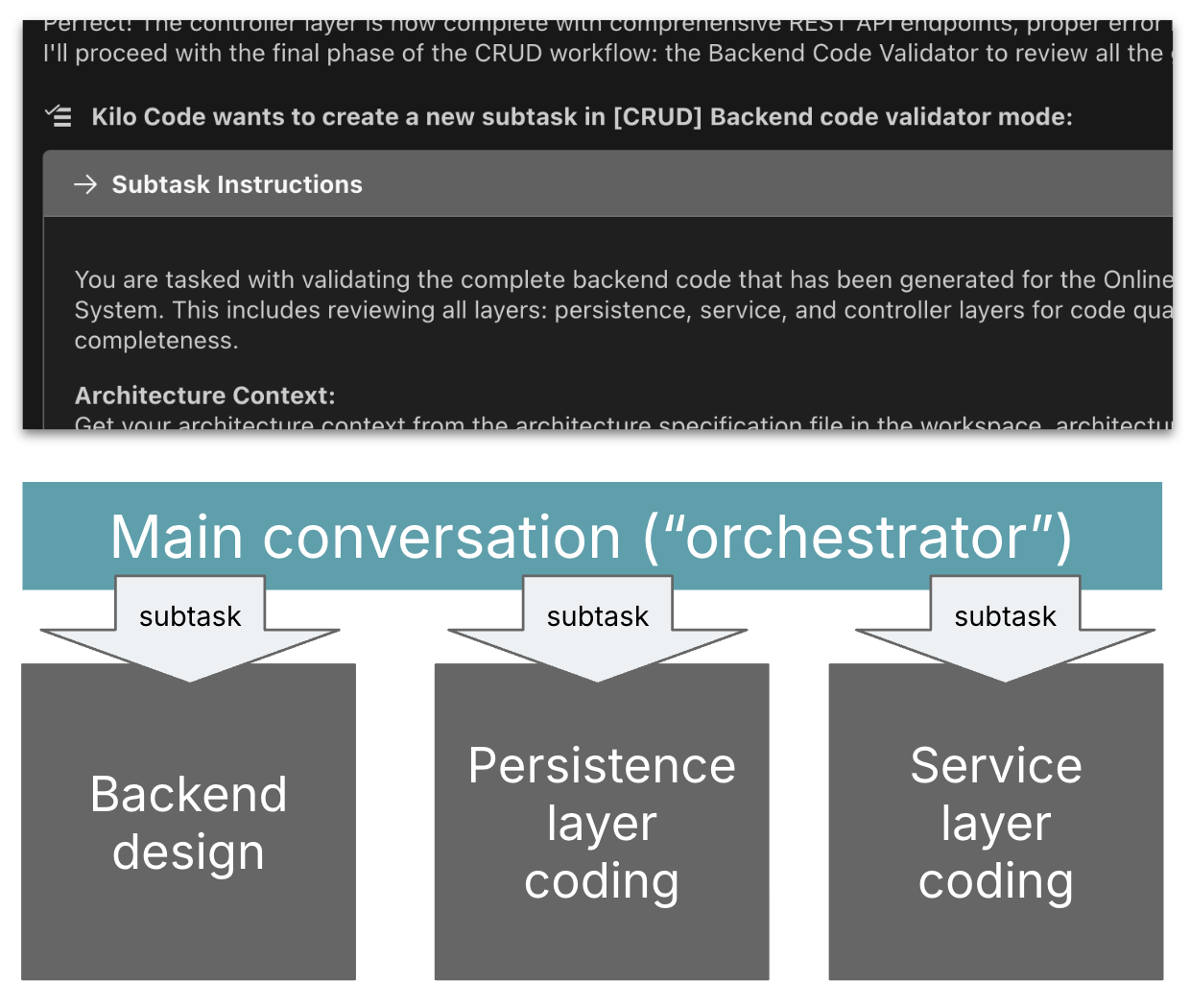
Figure 3: Subtasking setup in Kilo: An
orchestrator session delegates to subtask sessions
With a carefully curated allow-list of terminal commands, a human only
needs to hit “approve” here and there. We let it run in the background and
checked on it every now and then, and Kilo gave us a sound notification
whenever it needed input or an approval.
How can this increase the success rate?
Even though technically the context window sizes of LLMs are
increasing, LLM generation results still become more hit and miss the
longer a session becomes. Many coding assistants now offer the ability to
compress the context intermittently, but a common advice to coders using
agents is still that they should restart coding sessions as frequently as
possible.
Secondly, it is a very established prompting practice is to assign
roles and perspectives to LLMs to increase the quality of their results.
We could take advantage of that as well with this separation into multiple
agentic steps.
Stack-specific over general purpose
As you can maybe already tell from the workflow and its separation
into the typical controller, service and persistence layers, we didn’t
shy away from using techniques and prompts specific to the Spring target
stack.
How can this increase the success rate?
One of the key things people are excited about with Generative AI is
that it can be a general purpose code generator that can turn natural
language specifications into code in any stack. However, just telling
an LLM to “write a Spring Boot application” is not going to yield the
high quality and contextual code you need in a real-world digital
product scenario without further instructions (more on that in the
results section). So we wanted to see how stack-specific our setup would
have to become to make the results high quality and repeatable.
Use of deterministic scripts
For bootstrapping the application, we used a shell script rather than
having the LLM do this. After all, there is a CLI to create an up to
date, idiomatically structured Spring Boot application, so why would we
want AI to do this?
The bootstrapping step was the only one where we used this technique,
but it’s worth remembering that an agentic workflow like this by no
means has to be entirely up to AI, we can mix and match with “proper
software” wherever appropriate.
Code examples in prompts
Using example code snippets for the various patterns (Entity,
Repository, …) turned out to be the most effective strategy to get AI
to generate the type of code we wanted.
How can this increase the success rate?
Why do we need these code samples, why does it matter for our digital
products and business application software lens?
The simplest example from our experiment is the use of libraries. For
example, if not specifically prompted, we found that the LLM frequently
uses javax.persistence, which has been superseded by
jakarta.persistence. Extrapolate that example to a large engineering
organization that has a specific set of coding patterns, libraries, and
idioms that they want to use consistently across all their codebases.
Sample code snippets are a very effective way to communicate these
patterns to the LLM, and ensure that it uses them in the generated
code.
Also consider the use case of AI maintaining this application over time,
and not just creating its first version. We would want it to be ready to use
a new framework or new framework version as and when it becomes relevant, without
having to wait for it to be dominant in the model’s training data. We would
need a way for the AI tooling to reliably pick up on these library nuances.
Reference application as an anchor
It turned out that maintaining the code examples in the natural
language prompts is quite tedious. When you iterate on them, you don’t
get immediate feedback to see if your sample would actually compile, and
you also have to make sure that all the separate samples you provide are
consistent with each other.
To improve the developer experience of the developer implementing the
agentic workflow, we set up a reference application and an MCP (Model
Context Protocol) server that can provide the sample code to the agent
from this reference application. This way we could easily make sure that
the samples compile and are consistent with each other.
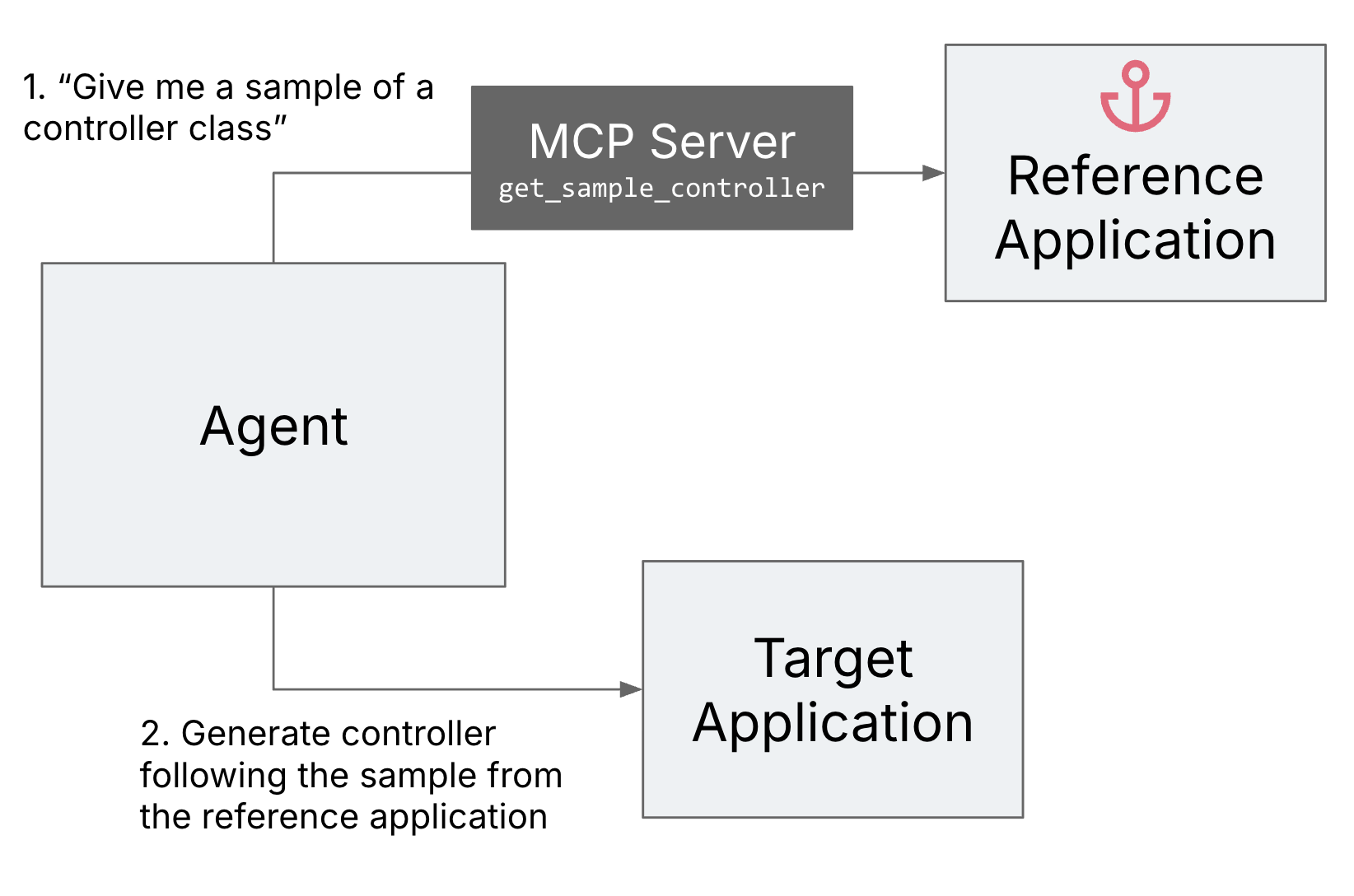
Figure 4: Reference application as an
anchor
Generate-review loops
We introduced a review agent to double check AI’s work against the
original prompts. This added an additional safety net to catch mistakes
and ensure the generated code adhered to the requirements and
instructions.
How can this increase the success rate?
In an LLM’s first generation, it often doesn’t follow all of the
instructions correctly, especially when there are a lot of them.
However, when asked to review what it created, and how it matches the
original instructions, it’s usually quite good at reasoning about the
fidelity of its work, and can fix many of its own mistakes.
Codebase modularization
We asked the AI to divide the domain into aggregates, and use those
to determine the package structure.
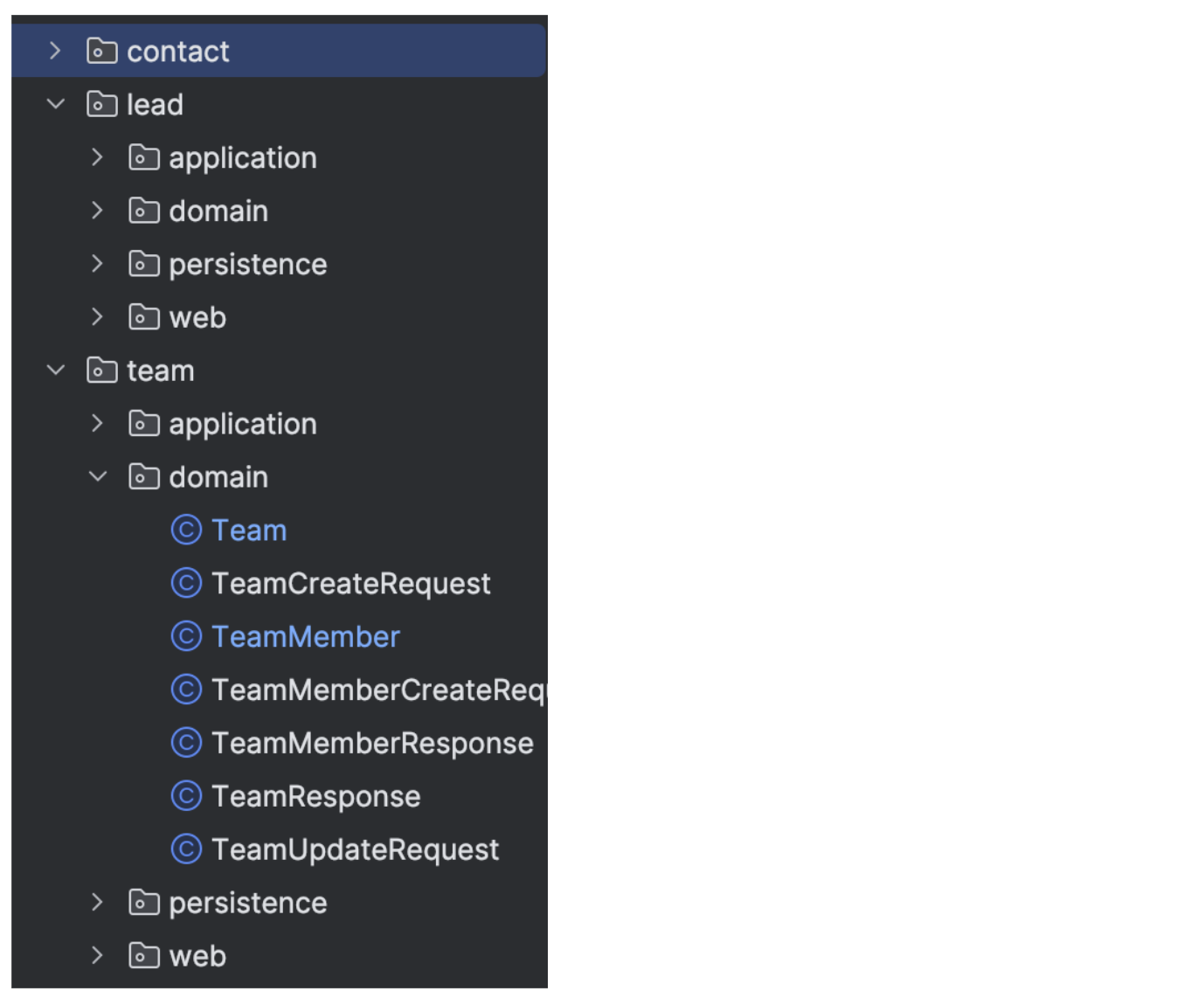
Figure 5: Sample of modularised
package structure
This is actually an example of something that was hard to get AI to
do without human oversight and correction. It is a concept that is also
hard for humans to do well.
Here is a prompt excerpt where we ask AI to
group entities into aggregates during the requirements analysis
step:
An aggregate is a cluster of domain objects that can be treated as a
single unit, it must stay internally consistent after each business
operation.
For each aggregate:
- Name root and contained entities
- Explain why this aggregate is sized the way it is
(transaction size, concurrency, read/write patterns).
We didn’t spend much effort on tuning these instructions and they can probably be improved,
but in general, it’s not trivial to get AI to apply a concept like this well.
How can this increase the success rate?
There are many benefits of code modularisation that
improve the quality of the runtime, like performance of queries, or
transactionality concerns. But it also has many benefits for
maintainability and extensibility – for both humans and AI:
- Good modularisation limits the number of places where a change needs to be
made, which means less context for the LLM to keep in mind during a change. - You can re-apply an agentic workflow like this one to one module at a time,
limiting token usage, and reducing the size of a change set. - Being able to clearly limit an AI task’s context to specific code modules
opens up possibilities to “freeze” all others, to reduce the chance of
unintended changes. (We did not try this here though.)
Results
Round 1: 3-5 entities
For most of our iterations, we used domains like “Simple product catalog”
or “Book tracking in a library”, and edited down the domain design done by the
requirements analysis phase to a maximum of 3-5 entities. The only logic in
the requirements were a few validations, other than that we just asked for
straightforward CRUD APIs.
We ran about 15 iterations of this category, with increasing sophistication
of the prompts and setup. An iteration for the full workflow usually took
about 25-30 minutes, and cost $2-3 of Anthropic tokens ($4-5 with
“thinking” enabled).
Ultimately, this setup could repeatedly generate a working application that
followed most of our specifications and conventions with hardly any human
intervention. It always ran into some errors, but could frequently fix its
own errors itself.
Round 2: Pre-existing schema with 10 entities
To crank up the size and complexity, we pointed the workflow at a
pared down existing schema for a Customer Relationship Management
application (~10 entities), and also switched from in-memory H2 to
Postgres. Like in round 1, there were a few validation and business
rules, but no logic beyond that, and we asked it to generate CRUD API
endpoints.
The workflow ran for 4–5 hours, with quite a few human
interventions in between.
As a second step, we provided it with the full set of fields for the
main entity, asked it to expand it from 15 to 50 fields. This ran
another 1 hour.
A game of whac-a-mole
Overall, we could definitely see an improvement as we were applying
more of the strategies. But ultimately, even in this quite controlled
setup with very specific prompting and a relatively simple target
application, we still found issues in the generated code all the time.
It’s a bit like whac-a-mole, every time you run the workflow, something
else happens, and you add something else to the prompts or the workflow
to try and mitigate that.
These were some of the patterns that are particularly problematic for
a real world business application or digital product:
Overeagerness
We frequently got additional endpoints and features that we did not
ask for in the requirements. We even saw it add business logic that we
didn’t ask for, e.g. when it came across a domain term that it knew how
to calculate. (“Pro-rated revenue, I know what that is! Let me add the
calculation for that.”)
Possible mitigation
Can be reigned in to an extent with the prompts, and repeatedly
reminding AI that we ONLY want what is specified. The reviewer agent can
also help catch some of the excess code (though we’ve seen the reviewer
delete too much code in its attempt to fix that). But this still
happened in some shape or form in almost all of our iterations. We made
one attempt at lowering the temperature to see if that would help, but
as it was only one attempt in an earlier version of the setup, we can’t
conclude much from the results.
Gaps in the requirements will be filled with assumptions
A priority: String field in an entity was assumed by AI to have the
value set “1”, “2”, “3”. When we introduced the expansion to more fields
later, even though we didn’t ask for any changes to the priority
field, it changed its assumptions to “low”, “medium”, “high”. Apart from
the fact that it would be a lot better to have introduced an Enum
here, as long as the assumptions stay in the tests only, it might not be
a big issue yet. But this could be quite problematic and have heavy
impact on a production database if it would happen to a default
value.
Possible mitigation
We’d somehow have to make sure that the requirements we give are as
complete and detailed as possible, and include a value set in this case.
But historically, we have not been great at that… We have seen some AI
be very helpful in helping humans find gaps in their requirements, but
the risk of incomplete or incoherent requirements always remains. And
the goal here was to test the boundaries of AI autonomy, so that
autonomy is definitely limited at this requirements step.
Brute force fixes
“[There is a ] lazy-loaded relationship that’s causing JSON
serialization problems. Let me fix this by adding @JsonIgnore to the
field”. Similar things have also happened to me multiple times in
agent-assisted coding sessions, from “the build is running out of
memory, let’s just allocate more memory” to “I can’t get the test to
work right now, let’s skip it for now and move on to the next task”.
Possible mitigation
We don’t have any idea how to prevent this.
Declaring success in spite of red tests
AI frequently claimed the build and tests were successful and moved
on to the next step, even though they were not, and even though our
instructions explicitly stated that the task is not done if build or
tests are failing.
Possible mitigation
This might be more easy to fix than the other things mentioned here,
by a more sophisticated agent workflow setup that has deterministic
checkpoints and does not allow the workflow to continue unless tests are
green. However, experience from agentic workflows in business process
automation have already shown that LLMs find ways to get around
that. In the case of code generation,
I would imagine they could still delete or skip tests to get beyond that
checkpoint.
Static code analysis issues
We ran SonarQube static code analysis on
two of the generated codebases, here is an excerpt of the issues that
were found:
| Issue | Severity | Sonar tags | Notes |
|---|---|---|---|
| Replace this usage of ‘Stream.collect(Collectors.toList())’ with ‘Stream.toList()’ and ensure that the list is unmodified. | Major | java16 | From Sonar’s “Why”: The key problem is that .collect(Collectors.toList()) actually returns a mutable kind of List while in the majority of cases unmodifiable lists are preferred. |
| Merge this if statement with the enclosing one. | Major | clumsy | In general, we saw a lot of ifs and nested ifs in the generated code, in particular in mapping and validation code. On a side note, we also saw a lot of null checks with `if` instead of the use of `Optional`. |
| Remove this unused method parameter “event”. | Major | cert, unused | From Sonar’s “Why”: A typical code smell known as unused function parameters refers to parameters declared in a function but not used anywhere within the function’s body. While this might seem harmless at first glance, it can lead to confusion and potential errors in your code. |
| Complete the task associated to this TODO comment. | Info | AI left TODOs in the code, e.g. “// TODO: This would be populated by joining with lead entity or separate service calls. For now, we’ll leave it null – it can be populated by the service layer” | |
| Define a constant instead of duplicating this literal (…) 10 times. | Critical | design | From Sonar’s “Why”: Duplicated string literals make the process of refactoring complex and error-prone, as any change would need to be propagated on all occurrences. |
| Call transactional methods via an injected dependency instead of directly via ‘this’. | Critical | From Sonar’s “Why”: A method annotated with Spring’s @Async, @Cacheable or @Transactional annotations will not work as expected if invoked directly from within its class. |
I would argue that all of these issues are relevant observations that lead to
harder and riskier maintainability, even in a world where AI does all the
maintenance.
Possible mitigation
It is of course possible to add an agent to the workflow that looks at the
issues and fixes them one by one. However, I know from the real world that not
all of them are relevant in every context, and teams often deliberately mark
issues as “won’t fix”. So there is still some nuance



