
When I was a computer science student in the 1980s, our digital alphabet was simple and small. We could express ourselves with the letters A..Z (and lowercase a..z) and numbers (0..9) and a handful of punctuation and symbols. Thanks to the ASCII standard, we could represent any of these characters in a single byte (actually just 7 bits). This allowed for a generous 128 different characters, and we had character slots to spare. (Of course for non-English and especially non-latin characters we had to resort to different code pages…but that was before the Internet forced us to work together. Before Unicode, we lived in a digital Tower of Babel.)
Even with the limited character set, pictorial communication was possible with ASCII through the fun medium of “ASCII art.” ASCII art is basically the stone-age version of emojis. For example, consider the shrug emoji: 🤷
Its text-art ancestor (not strictly ASCII as a sharp reader pointed out) is this: ¯\_(ツ)_/¯ While ASCII and text art currently enjoys a retro renaissance, the emoji has become indispensable in our daily communications.
 I’m publishing this article to match the timing of World Emoji Day, which happens on July 17. If you ever forget the date of this important event, just look at the traditional calendar emoji for a reminder!
I’m publishing this article to match the timing of World Emoji Day, which happens on July 17. If you ever forget the date of this important event, just look at the traditional calendar emoji for a reminder!
(Update: I first published this article in 2021. I’ve updated it to include code that references the most recent Unicode emoji standards.)
Emojis before Unicode
Given the ubiquity of emojis in every communication channel, it’s sometimes difficult to remember that just a few years ago emoji characters were devised and implemented in vendor-specific offerings. As the sole Android phone user in my house, I remember a time when my iPhone-happy family could express themselves in emojis that I couldn’t read in the family group chat. Apple would release new emojis for their users, and then Android (Google) would leap frog with another set of their own fun symbols. But if you weren’t trading messages with users of the same technology, then chunks of your text would be lost in translation.
Enter Unicode. A standard system for encoding characters that allows for multiple bytes of storage, Unicode has seemingly endless runway for adding new characters. More importantly, there is a standards body that sets revisions for Unicode characters periodically so everyone can use the same huge alphabet. In 2015, emoji characters were added into Unicode and have been revised steadily with universal agreement.
This standardization has helped to propel emojis as a main component of communication in every channel. Text messages, Twitter threads, Venmo payments, Facebook messages, Slack messages, GitHub comments — everything accepts emojis. (Emojis are so ingrained and expected that if you send a Venmo payment without using an emoji and just use plain text, it could be interpreted as a slight or at the least as a miscue.)
For more background about emojis, read How Emjois Work (source: How Stuff Works).
Unicode is essential for emojis. In SAS, the use of Unicode is possible by way of UTF-8 encoding. If you work in a modern SAS environment with a diverse set of data, you should already be using ENCODING=UTF8 as your SAS session encoding. If you use SAS OnDemand for Academics (the free environment for any learner), this is already set for you. And SAS Viya offers only UTF-8 — which makes sense, because it’s the best for most data and it’s how most apps work these days.
Emojis as data and processing in SAS
Emojis are everywhere, and their presence can enrich (and complicate) the way that we analyze text data. For example, emojis are often useful cues for sentiment (smiley face! laughing-with-tears face! grimace face! poop!). It’s not unusual for a text message to be ALL emojis with no “traditional” words.
The website Unicode.org maintains the complete compendium of emojis as defined in the latest standards. They also provide the emoji definitions as data files, which we can easily read into SAS. This program reads all of the data as published and adds features for just the “basic” emojis:
/* MUST be running with ENCODING=UTF8 */ filename raw temp; proc http url="https://unicode.org/Public/emoji/latest/emoji-sequences.txt" out=raw; run; ods escapechar='~'; data emojis (drop=line); length line $ 1000 codepoint_range $ 45 val_start 8 val_end 8 type $ 30 comments $ 65 saschar $ 20 htmlchar $ 25; infile raw ; input; line = _infile_; /* skip comments and blank lines */ /* data fields are separated by semicolons */ if substr(line,1,1)^='#' and line ^= ' ' then do; /* read the raw codepoint value - could be single, a range, or a combo of several */ codepoint_range = scan(line,1,';'); /* read the type field */ type = compress(scan(line,2,';')); /* text description of this emoji */ comments = scan(line,3,'#;'); /* for those emojis that have a range of values */ val_start = input(scan(codepoint_range,1,'. '), hex.); if find(codepoint_range,'..') > 0 then do; val_end = input(scan(codepoint_range,2,'.'), hex.); end; else val_end=val_start; if type = "Basic_Emoji" then do; saschar = cat('~{Unicode ',scan(codepoint_range,1,' .'),'}'); htmlchar = cats('',scan(codepoint_range,1,' .'),';'); end; output; end; run; /* Assuming HTML or HTML5 output destination */ /* print the first 50 emoji records */ proc print data=emojis (obs=50); run; |
(As usual, all of the SAS code in this article is available on GitHub.)
The “features” I added include the Unicode representation for an emoji character in SAS, which could then be used in any SAS report in ODS or any graphics produced in the SG procedures. I also added the HTML-encoded representation of the emoji, which uses the form NNNN; where NNNN is the Unicode value for the character. Here’s the raw data view:
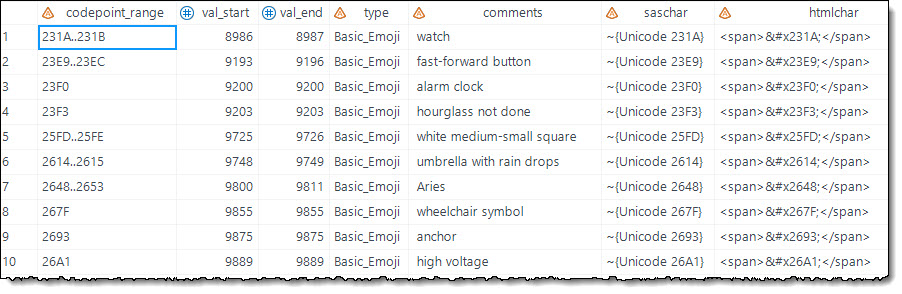
When you PROC PRINT to an HTML destination, here’s the view in the results browser:
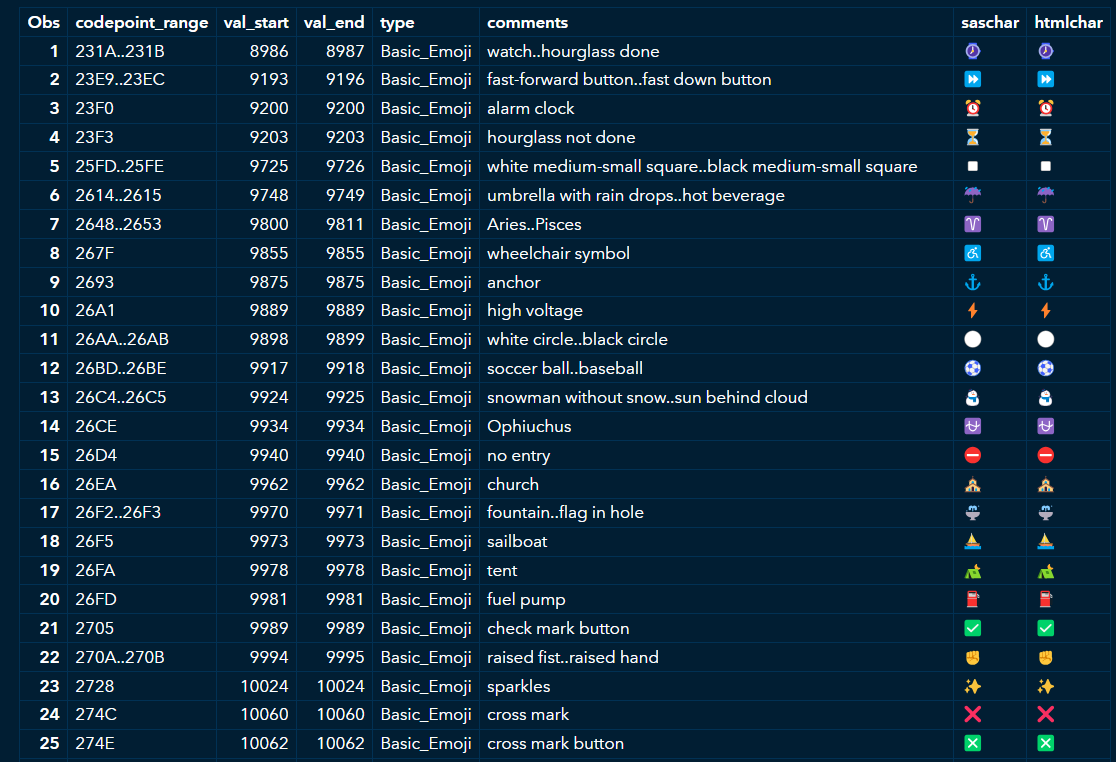
In search of structured emoji data
The Unicode.org site can serve up the emoji definitions and codes, but this data isn’t exactly ready for use within applications. One could work through the list of emojis (thousands of them!) and tag these with descriptive words and meanings. That could take a long time and to be honest, I’m not sure I could accurately interpret many of the emojis myself. So I began the hunt for data files that had this work already completed.
I found the GitHub/gemoji project, a Ruby-language code repository that contains a structured JSON file that describes a recent collection of emojis. From all of the files in the project, I need only one JSON file. Here’s a SAS program that downloads the file with PROC HTTP and reads the data with the JSON libname engine:
filename rawj temp; proc http url="https://raw.githubusercontent.com/github/gemoji/master/db/emoji.json" out=rawj; run; libname emoji json fileref=rawj; |
Upon reading these data, I quickly realized the JSON text contains the actual Unicode character for the emoji, and not the decimal or hex value that we might need for using it later in SAS.

I wanted to convert the emoji character to its numeric code. That’s when I discovered the UNICODEC function, which can “decode” the Unicode sequence into its numeric values. (Note that some characters use more than one value in a sequence).
Here’s my complete program, which includes some reworking of the tags and aliases attributes so I can have one record per emoji:
filename rawj temp; proc http url="https://raw.githubusercontent.com/github/gemoji/master/db/emoji.json" out=rawj; run; libname emoji json fileref=rawj; /* reformat the tags and aliases data for inclusion in a single data set */ data tags; length ordinal_root 8 tags $ 60; set emoji.tags; tags = catx(', ',of tags:); keep ordinal_root tags; run; data aliases; length ordinal_root 8 aliases $ 60; set emoji.aliases; aliases = catx(', ',of aliases:); keep ordinal_root aliases; run; /* Join together in one record per emoji */ proc sql; create table full_emoji as select t1.emoji as emoji_char, unicodec(t1.emoji,'esc') as emoji_code, t1.description, t1.category, t1.unicode_version, case when t1.skin_tones = 1 then t1.skin_tones else 0 end as has_skin_tones, t2.tags, t3.aliases from emoji.root t1 left join tags t2 on (t1.ordinal_root = t2.ordinal_root) left join aliases t3 on (t1.ordinal_root = t3.ordinal_root) ; quit; proc print data=full_emoji; run; |
Here’s a snippet of the report that includes some of the more interesting sequences:
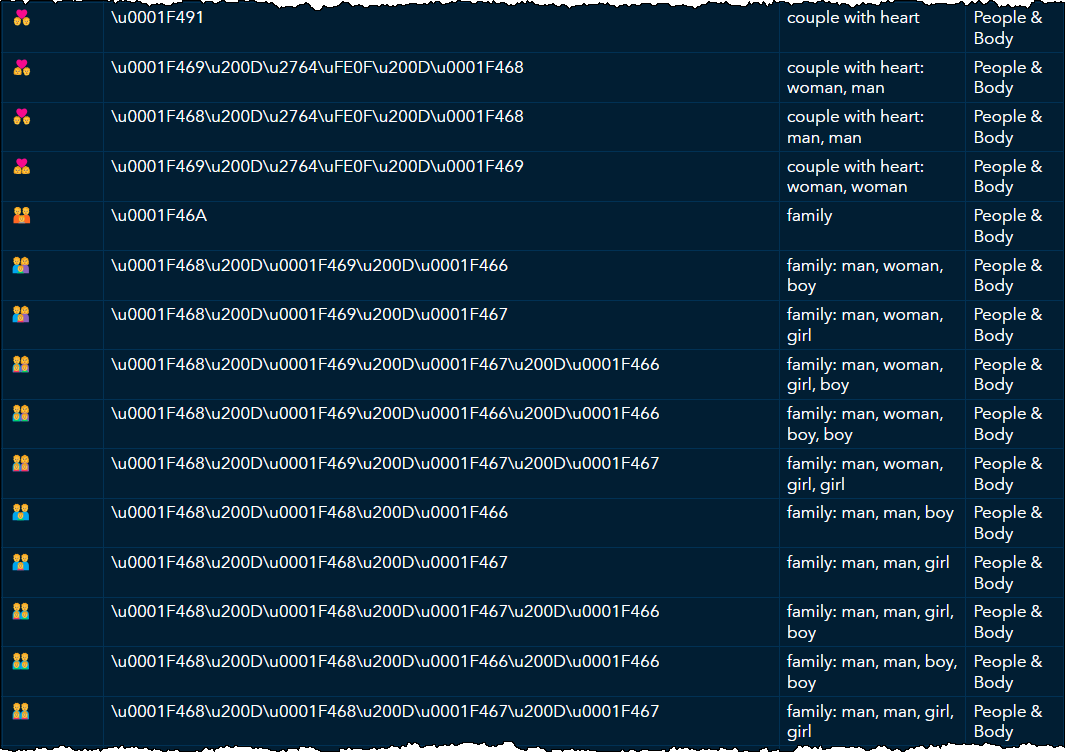
The diversity and inclusion aspect of emoji glyphs is ever-expanding. For example, consider the emoji for “family”:
- The basic family emoji code is \u0001F46A (👪)
- But since families come in all shapes and sizes, you can find a family that better represents you. For example, how about “family: man, man, girl, girl”? The code is
\u0001F468\u200D\u0001F468\u200D\u0001F467\u200D\u0001F467, which includes the codes for each component “member” all smooshed together with a “zero-width joiner” (ZWJ) code in between (👨👨👧👧) - All of the above, but with a dark-skin-tone modifier (\u0001F3FF) for 2 of the family members:
\u0001F468\u0001F3FF\u200D\u0001F468\u200D\u0001F467\u200D\u0001F467\u0001F3FF(👨🏿👨👧👧🏿)
Note: I noticed that not all browsers have caught up on rendering that last example. In my browser it looks like this:
Conclusion: Emojis reflect society, and society adapts to emojis
As you might have noticed from that last sequence I shared, a single concept can call for many different emojis. As our society becomes more inclusive around gender, skin color, and differently capable people, emojis are keeping up. Everyone can express the concept in the way that is most meaningful for them. This is just one way that the language of emojis enriches our communication, and in turn our experience feeds back into the process and grows the emoji collection even more.
As emoji-rich data is used for reporting and for training of AI models, it’s important for our understanding of emoji context and meaning to keep up with the times. Already we know that emoji use differs among different age generations and across other demographic groups. The use and application of emojis — separate from the definition of emoji codes — is yet another dimension to the data.
Our task as data scientists is to bring all of this intelligence and context into the process when we parse, interpret and build training data sets. The mechanics of parsing and producing emoji-rich data is just the start.
If you’re encountering emojis in your data and considering them in your reporting and analytics, please let me know how! I’d love to hear from you in the comments.



